Spark Performance Optimization Series: #1. Skew
By A Mystery Man Writer
Last updated 23 Sept 2024

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Apache Spark Performance is too hard. Let's make it easier

High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark: Karau, Holden, Warren, Rachel: 9781491943205: : Books

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai

Using different partitioning methods in Spark to help with data skew - Cloud Fundis

List: Reading list, Curated by mohit chaurasia

Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai
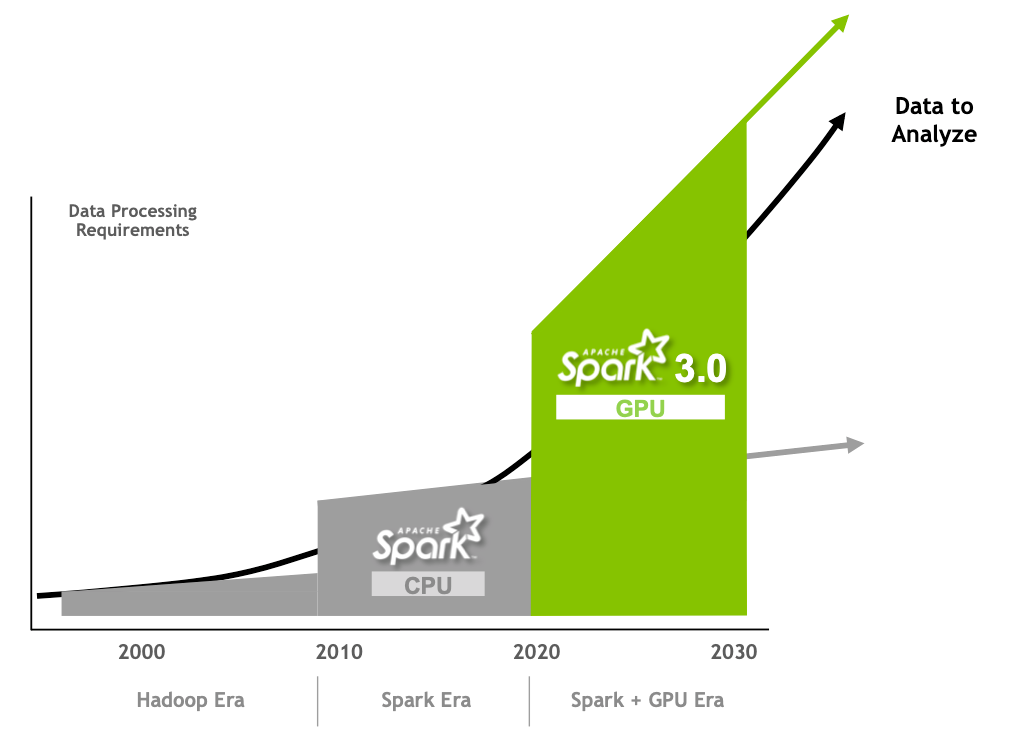
Optimizing and Improving Spark 3.0 Performance with GPUs
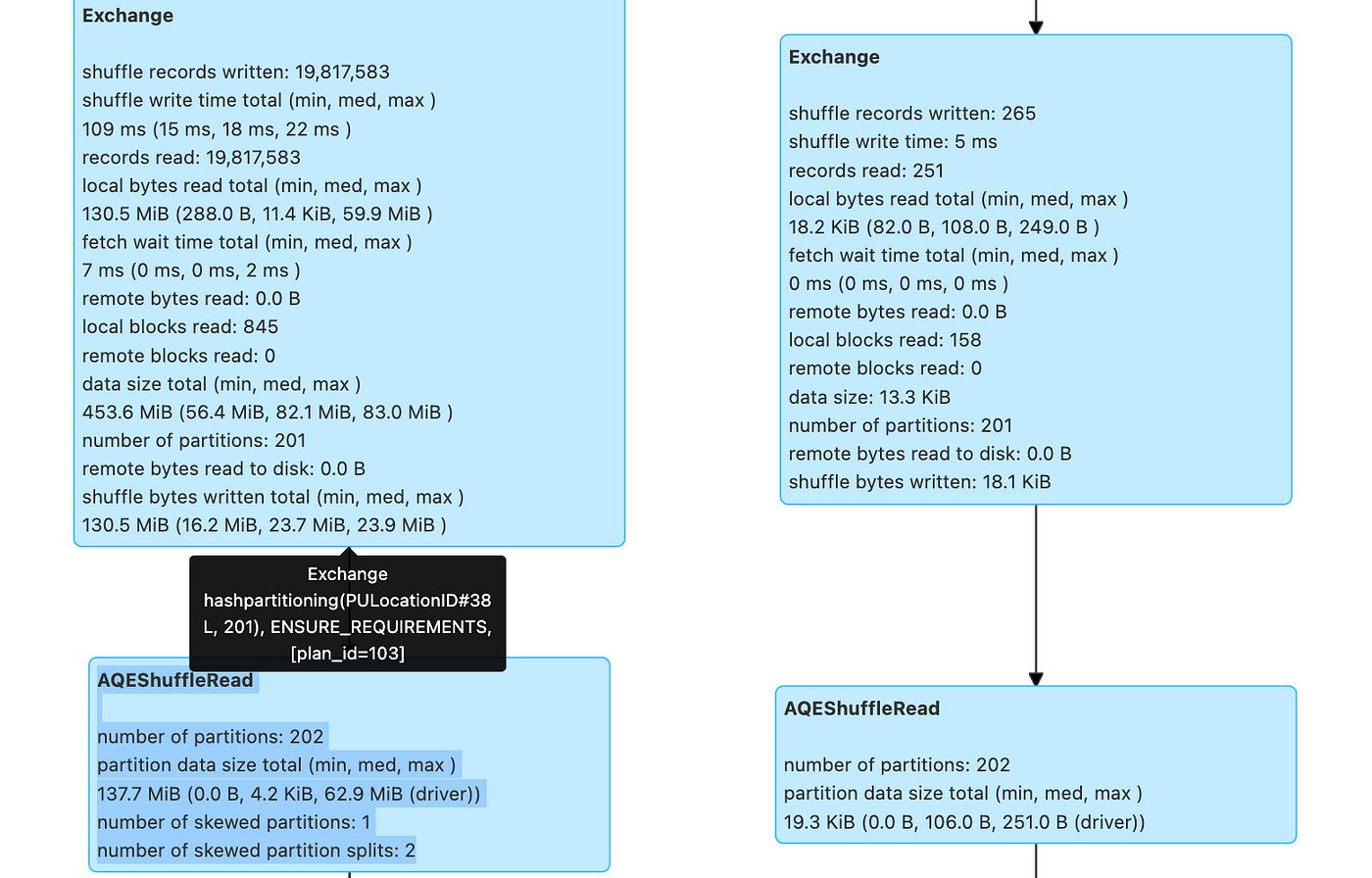
Handling Data Skew in Apache Spark: Techniques, Tips and Tricks to Improve Performance, by Suffyan Asad

List: Reading list, Curated by mohit chaurasia
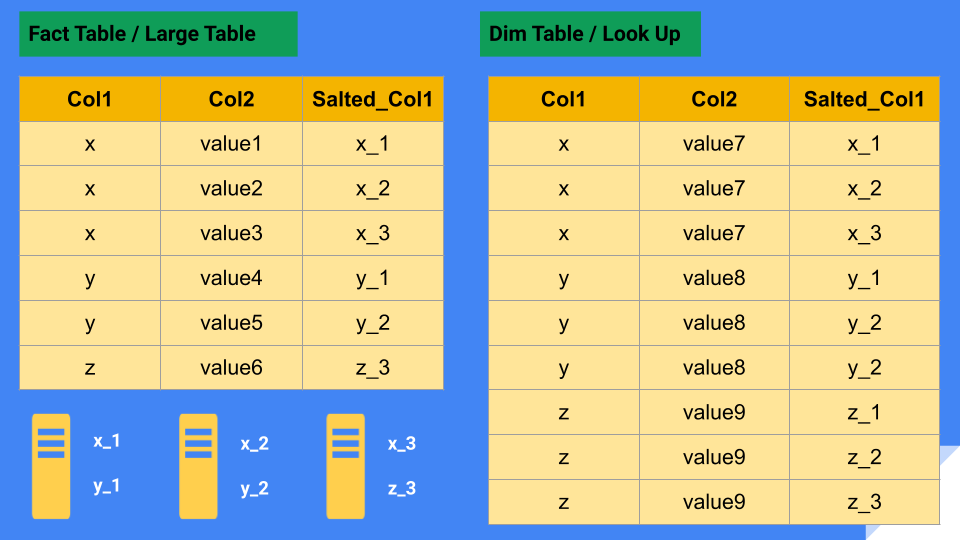
The 5S Spark Optimization Series, Part 2: Tackling Skew Optimization for Balanced Excellence!, by Chenglong Wu

Kubernetes Architecture,Hands On!, by Himansu Sekhar

Understanding common Performance Issues in Apache Spark - Deep Dive: Data Skew, by Michael Heil
Recommended for you
 No Girl Can Make It Through These 11 Questions Without Cringing14 Jul 2023
No Girl Can Make It Through These 11 Questions Without Cringing14 Jul 2023- Ass Punishment Quiz14 Jul 2023
- Lesbian slave punishment quiz14 Jul 2023
 A Toda Madre Quiz July 6th 2022.pptx14 Jul 2023
A Toda Madre Quiz July 6th 2022.pptx14 Jul 2023 I Smell a Pop Quiz!: A Big Nate Book: Peirce, Lincoln14 Jul 2023
I Smell a Pop Quiz!: A Big Nate Book: Peirce, Lincoln14 Jul 2023 Reduce Back Pain With A Wedgie14 Jul 2023
Reduce Back Pain With A Wedgie14 Jul 2023 11: Swamp Ass Summer - by Ariana Newhouse14 Jul 2023
11: Swamp Ass Summer - by Ariana Newhouse14 Jul 2023 What wedgie do you deserve (boys only) Comments, Page 114 Jul 2023
What wedgie do you deserve (boys only) Comments, Page 114 Jul 2023 Wedgie Punishment14 Jul 2023
Wedgie Punishment14 Jul 2023 Killer wedgie. Lol Funny horror, Horror movies funny, Horror movies memes14 Jul 2023
Killer wedgie. Lol Funny horror, Horror movies funny, Horror movies memes14 Jul 2023
You may also like
- egoistunderwear.com JeanPaul Paula wearing Sugar Rush 🍭 series by PUMP! Briefs/14 Jul 2023
- NEW BONUS FLOW 33 Min Foam-Roller Sculpt & Restore, Connect Breath to Movement as we Release Tension, Increase Blood Flow & Collagen…14 Jul 2023
:max_bytes(150000):strip_icc():focal(719x319:721x321)/katie-holmes-c6405942990c44959fbeda05b7abf359.jpg) 21 Celebrities Wearing Face Masks and Where to Shop Them14 Jul 2023
21 Celebrities Wearing Face Masks and Where to Shop Them14 Jul 2023 Buy Black Fleece Lined Thermal Tights from Next United Arab Emirates14 Jul 2023
Buy Black Fleece Lined Thermal Tights from Next United Arab Emirates14 Jul 2023 35% Off Anoeses Discount Code, Coupons (2 Active) Mar '2414 Jul 2023
35% Off Anoeses Discount Code, Coupons (2 Active) Mar '2414 Jul 2023 Sombra de ojos (Hey Girl), D'Hermosa14 Jul 2023
Sombra de ojos (Hey Girl), D'Hermosa14 Jul 2023 Harajuku Gothic Plaid Skirts – Aesthetic Clothes Store14 Jul 2023
Harajuku Gothic Plaid Skirts – Aesthetic Clothes Store14 Jul 2023 Cinturón / faja para levantamiento de pesas14 Jul 2023
Cinturón / faja para levantamiento de pesas14 Jul 2023 Love Island's Kady McDermott flaunts her toned figure in white14 Jul 2023
Love Island's Kady McDermott flaunts her toned figure in white14 Jul 2023 EMPETUA High-Waisted Shaping Black Leggings Women Size XL14 Jul 2023
EMPETUA High-Waisted Shaping Black Leggings Women Size XL14 Jul 2023

