The LLM Triad: Tune, Prompt, Reward - Gradient Flow
By A Mystery Man Writer
Last updated 21 Sept 2024

As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"
Fine-Tuning LLMs with Direct Preference Optimization
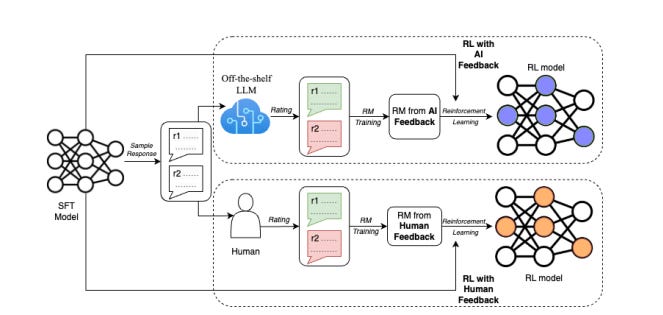
Understanding RLHF for LLMs

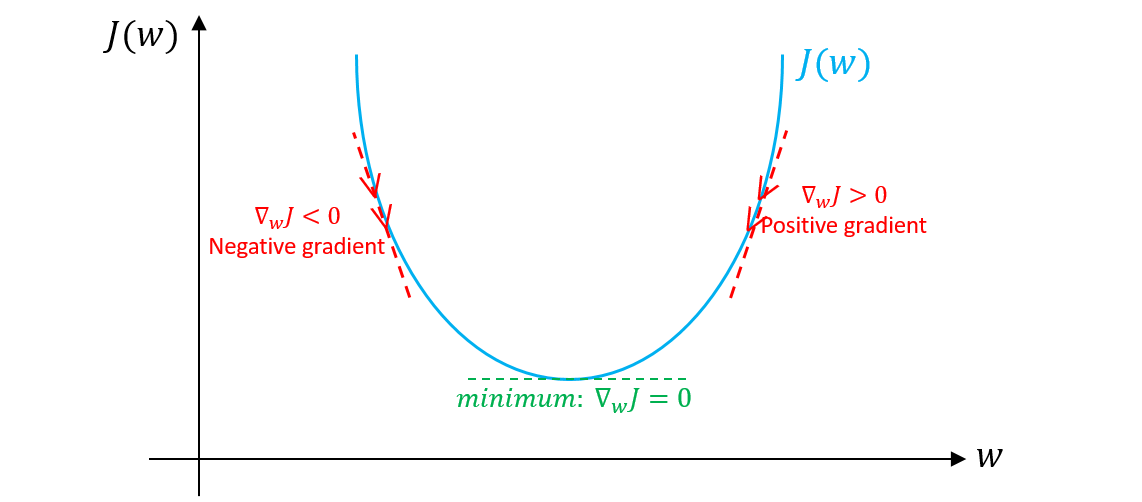
How to Fine Tune LLM Using Gradient
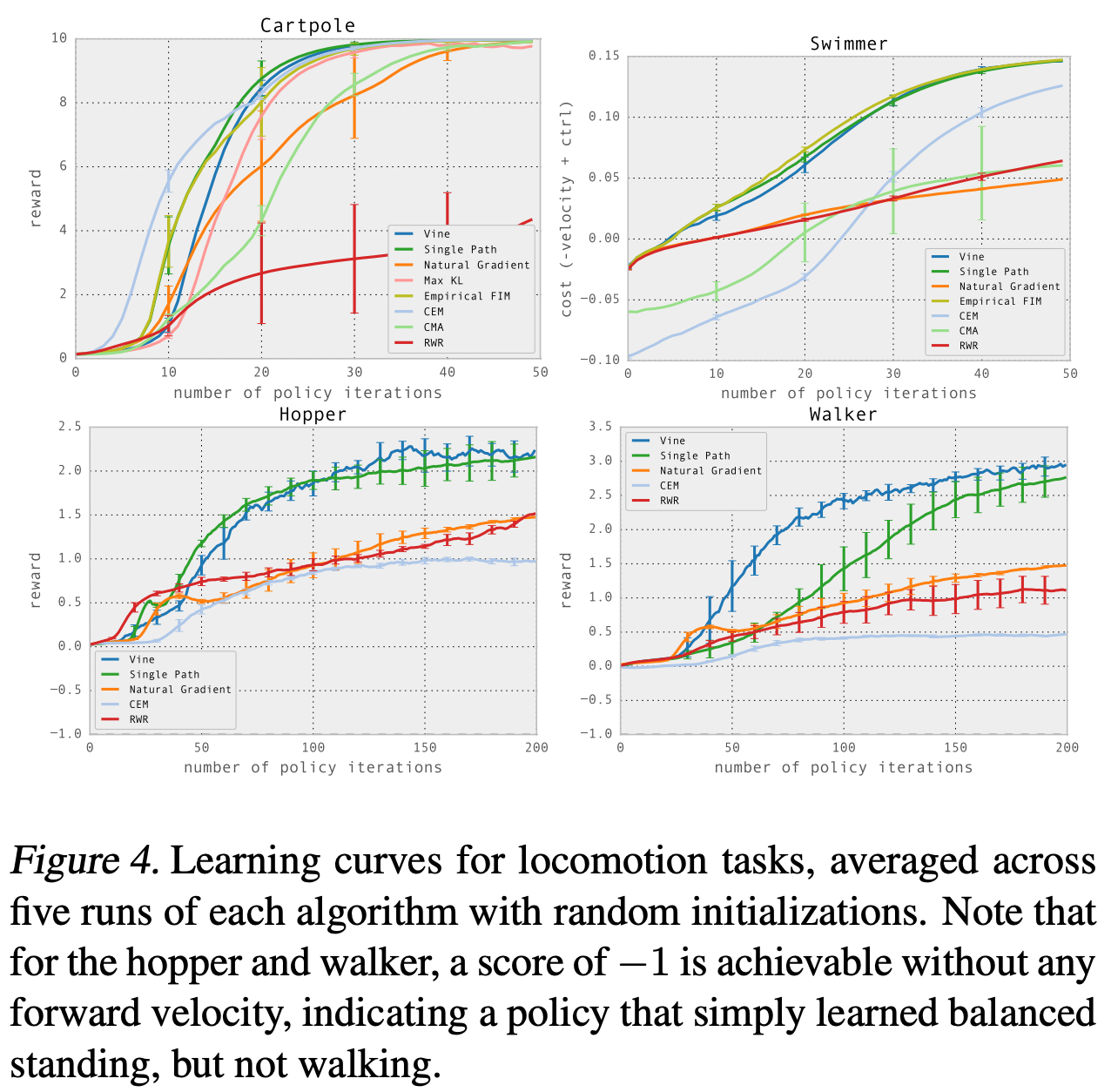
NeurIPS 2022
Proximal Policy Optimization (PPO): The Key to LLM Alignment

Building an LLM Stack Part 3: The art and magic of Fine-tuning
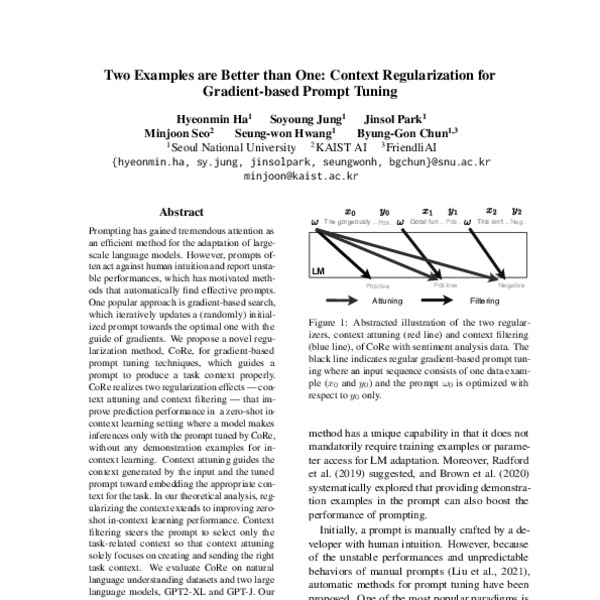
Two Examples are Better than One: Context Regularization for Gradient-based Prompt Tuning - ACL Anthology

Gradient Flow
7 Must-Have Features for Crafting Custom LLMs
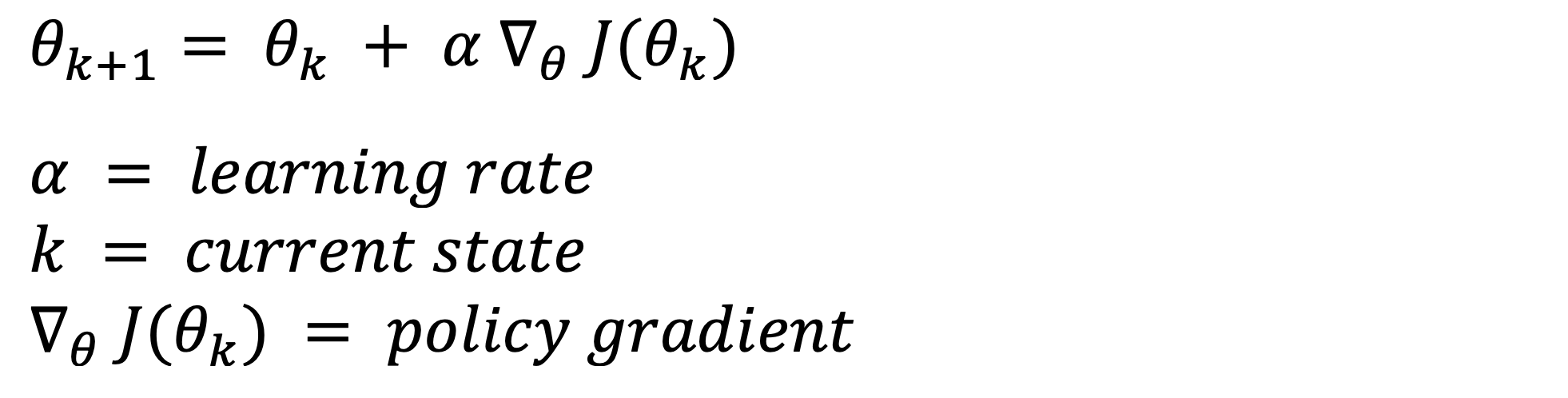
Understanding RLHF for LLMs
📝 Guest Post: How to Maximize LLM Performance*
.png)
A Comprehensive Guide to fine-tuning LLMs using RLHF (Part-1)

NeurIPS 2022

Reinforcement Learning from Human Feedback (RLHF), by kanika adik
Recommended for you
 Complete Guide On Fine-Tuning LLMs using RLHF14 Jul 2023
Complete Guide On Fine-Tuning LLMs using RLHF14 Jul 2023 Fine-tuning in Deep Learning. How fine-tuning is used and why14 Jul 2023
Fine-tuning in Deep Learning. How fine-tuning is used and why14 Jul 2023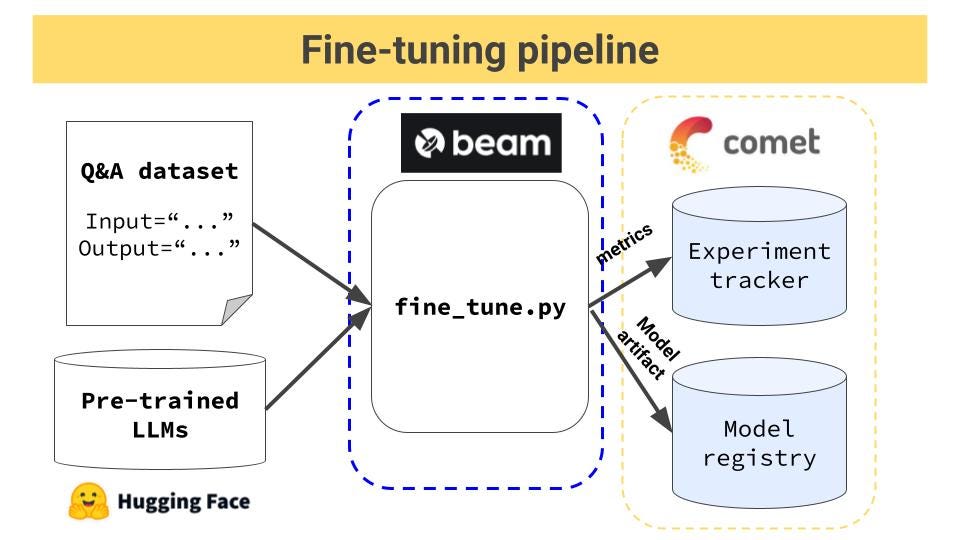 Fine tuning pipeline for open-source LLMs14 Jul 2023
Fine tuning pipeline for open-source LLMs14 Jul 2023 How to Fine-tune Mixtral 8x7b with Open-source Ludwig - Predibase14 Jul 2023
How to Fine-tune Mixtral 8x7b with Open-source Ludwig - Predibase14 Jul 2023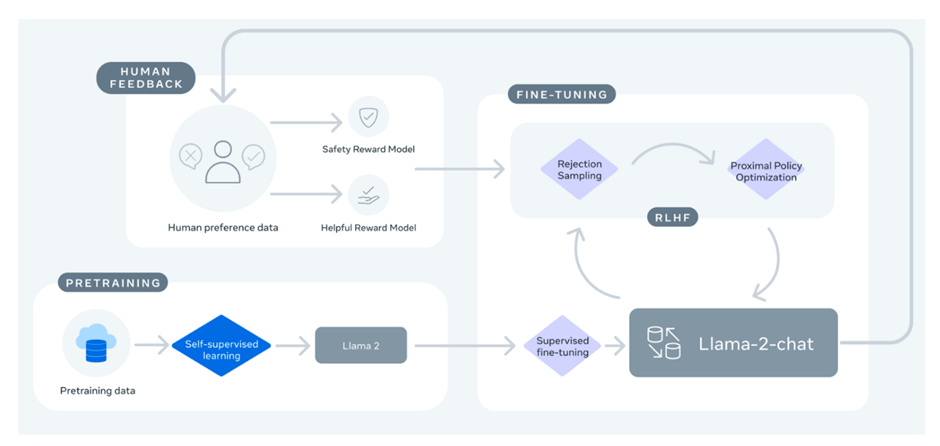 Fine-Tune Your Own Llama 2 Model in a Colab Notebook14 Jul 2023
Fine-Tune Your Own Llama 2 Model in a Colab Notebook14 Jul 2023 Fine-tuning a Neural Network explained - deeplizard14 Jul 2023
Fine-tuning a Neural Network explained - deeplizard14 Jul 2023 Cerebras Announces Fine-Tuning on the Cerebras AI Model Studio - Cerebras14 Jul 2023
Cerebras Announces Fine-Tuning on the Cerebras AI Model Studio - Cerebras14 Jul 2023 Fine-Tuning Large language Models: A Comprehensive Guide, by Ankush Mulkar14 Jul 2023
Fine-Tuning Large language Models: A Comprehensive Guide, by Ankush Mulkar14 Jul 2023 Fine Tuning Formlabs LFS printers14 Jul 2023
Fine Tuning Formlabs LFS printers14 Jul 2023 AF Fine-Tuning Options14 Jul 2023
AF Fine-Tuning Options14 Jul 2023
You may also like
- AI Art: AI Artwork by @unicorn009614 Jul 2023
 Victoria's Secret14 Jul 2023
Victoria's Secret14 Jul 2023 Wild Fable Computer & Office Athletic Leggings for Women14 Jul 2023
Wild Fable Computer & Office Athletic Leggings for Women14 Jul 2023 16 Elevated Converse Outfits That Look So Darn Good14 Jul 2023
16 Elevated Converse Outfits That Look So Darn Good14 Jul 2023 FYMNSI Men's Thong Bikini G-String Briefs Underwear Mesh Sheer Lace Panties See Through Transparent Lingerie Sissy Underpants14 Jul 2023
FYMNSI Men's Thong Bikini G-String Briefs Underwear Mesh Sheer Lace Panties See Through Transparent Lingerie Sissy Underpants14 Jul 2023 Women's Underwire Sport Bra,Black,36DDD14 Jul 2023
Women's Underwire Sport Bra,Black,36DDD14 Jul 2023 Girls 1 Pair Heat Holders 0.52 Tog Thermal Tights14 Jul 2023
Girls 1 Pair Heat Holders 0.52 Tog Thermal Tights14 Jul 2023 lindsey roupa Vestido Longo Feminina Lastex Com Alça Em Tiras De14 Jul 2023
lindsey roupa Vestido Longo Feminina Lastex Com Alça Em Tiras De14 Jul 2023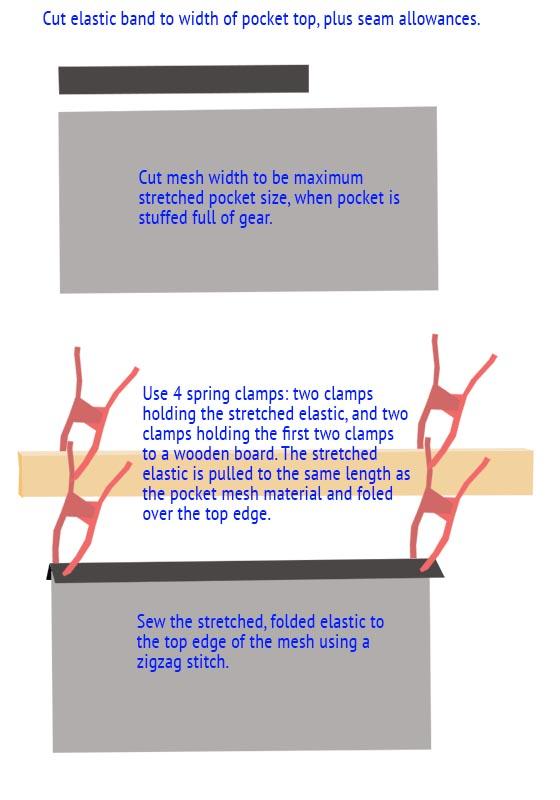 Sewing Tips for Elastic Band and Stuff Pocket Fabric? - Backpacking Light14 Jul 2023
Sewing Tips for Elastic Band and Stuff Pocket Fabric? - Backpacking Light14 Jul 2023 Outlet Deal, Bohemian Box Braid with Curl 14-16 Inch14 Jul 2023
Outlet Deal, Bohemian Box Braid with Curl 14-16 Inch14 Jul 2023
